Before we answer that question, let’s go over some motivation.
Motivation
The WNBA Draft is an annual event in which teams select eligible college players and international prospects to join the league, shaping the next generation of professional women’s basketball talent. Similar to other professional sports drafts, selection order is largely determined by the previous season’s standings, with weaker teams given higher picks in an effort to maintain competitive balance. For general managers, the draft represents a critical decision point: players are evaluated not only on traditional box-score statistics such as points, rebounds, and assists, but also on efficiency measures, defensive contributions, and advanced indicators of value like win shares.
In this analysis, we treat the draft as a decision problem where the goal is to identify players who are likely to provide the greatest overall impact at the professional level. Using available collegiate and pre-draft performance metrics—including per-game production, shooting efficiency (field goal, three-point, and free throw percentages), and all-around contributions such as steals, blocks, and turnovers—we aim to build a data-driven framework for player selection. This approach allows us to move beyond draft position alone and systematically compare prospects based on their statistical profiles and projected value to a WNBA roster.
… so why the WNBA?
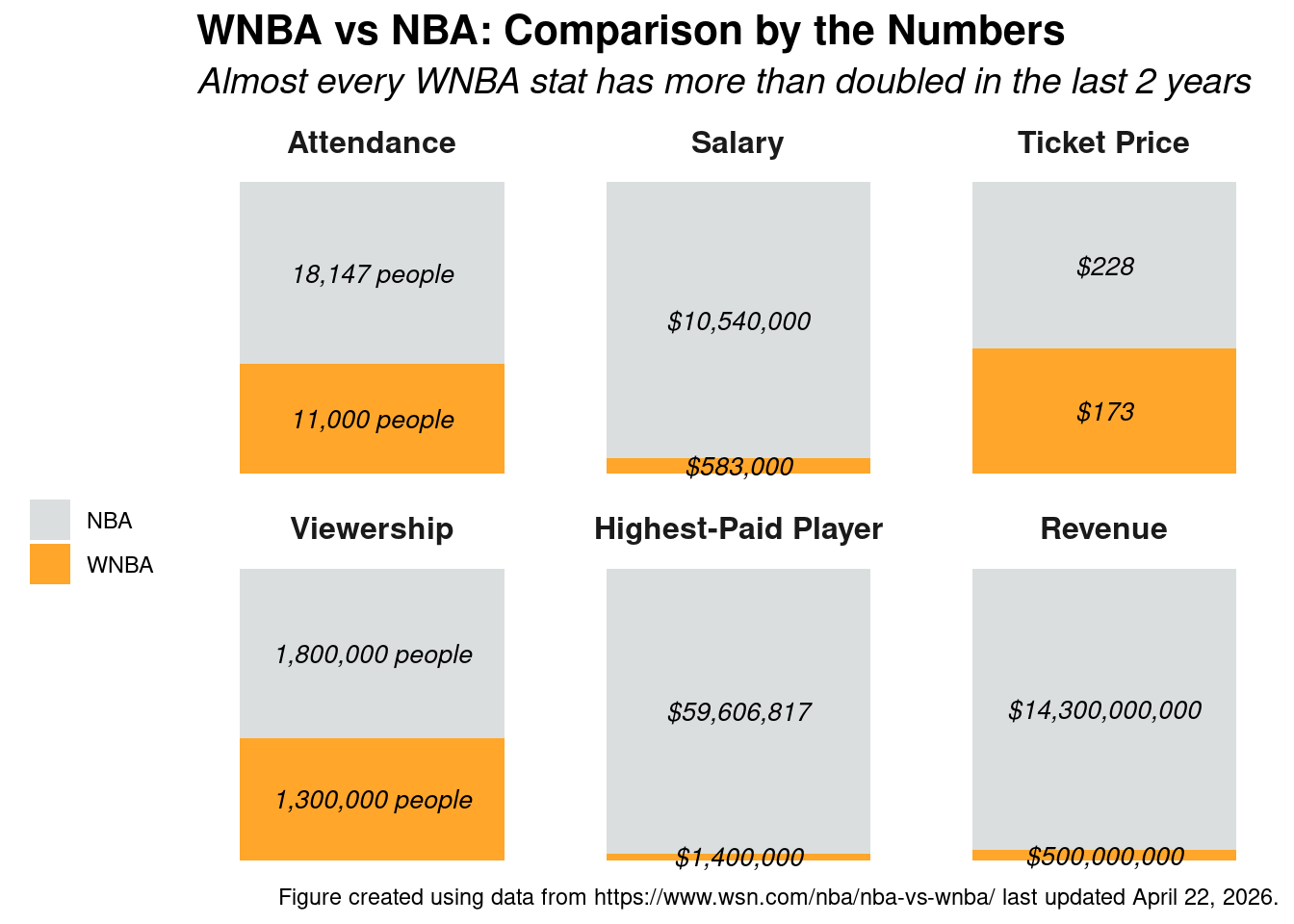
We wanted to understand what factors contribute to a WNBA player succeeding in the league. Given that the WNBA is a newer and more developing league, trends are not as established as they are in the NBA. Does height play a bigger role than weight? Does being selected early in the draft guarantee a more productive career? These are the kinds of questions that motivated us to look more closely at the data the league has generated over its nearly three decades of existence.
This brings us to our research question:
What factors influence the success of a WNBA player?
Data
To answer that question, we assembled a dataset covering every player season recorded in the WNBA from 1997 to 2025
drawing from Basketball Reference as our primary source.
1997-2025
The final dataset contains
across
filtered to players with at least five minutes per game.
1,011 unique players
4,828 player seasons
Each observation captures the following player statistics:
in addition to per game statistics like:
as well as our predictor variable:
Win shares is a single number that attempts to credit each player with a portion of their team’s wins based on both their offensive and defensive contributions. A player averaging around 1.3 win shares in a season is performing near the league median. A player generating 5 or more in a season is among the most impactful in the league that year.
Player Statistics
year
position
team
university
country of origin
draft year
draft pick
height
weight
Per Game Statistics
points
rebounds
assists
blocks
steals
turnovers
shooting percentages
Win Shares
To explore the data visually, we examined how win shares are distributed across the full dataset, how they vary by position and era, and how individual statistics relate to overall contributions. We built several regression models ranging from a standard OLS regression on performance statistics, to a physical attributes only model, to a combined model, and finally a random forest to capture nonlinear structure and rank feature importance across all predictors simultaneously.
Results
One thing we looked at was player positions. Specifically, how player position was related to a player’s win shares.
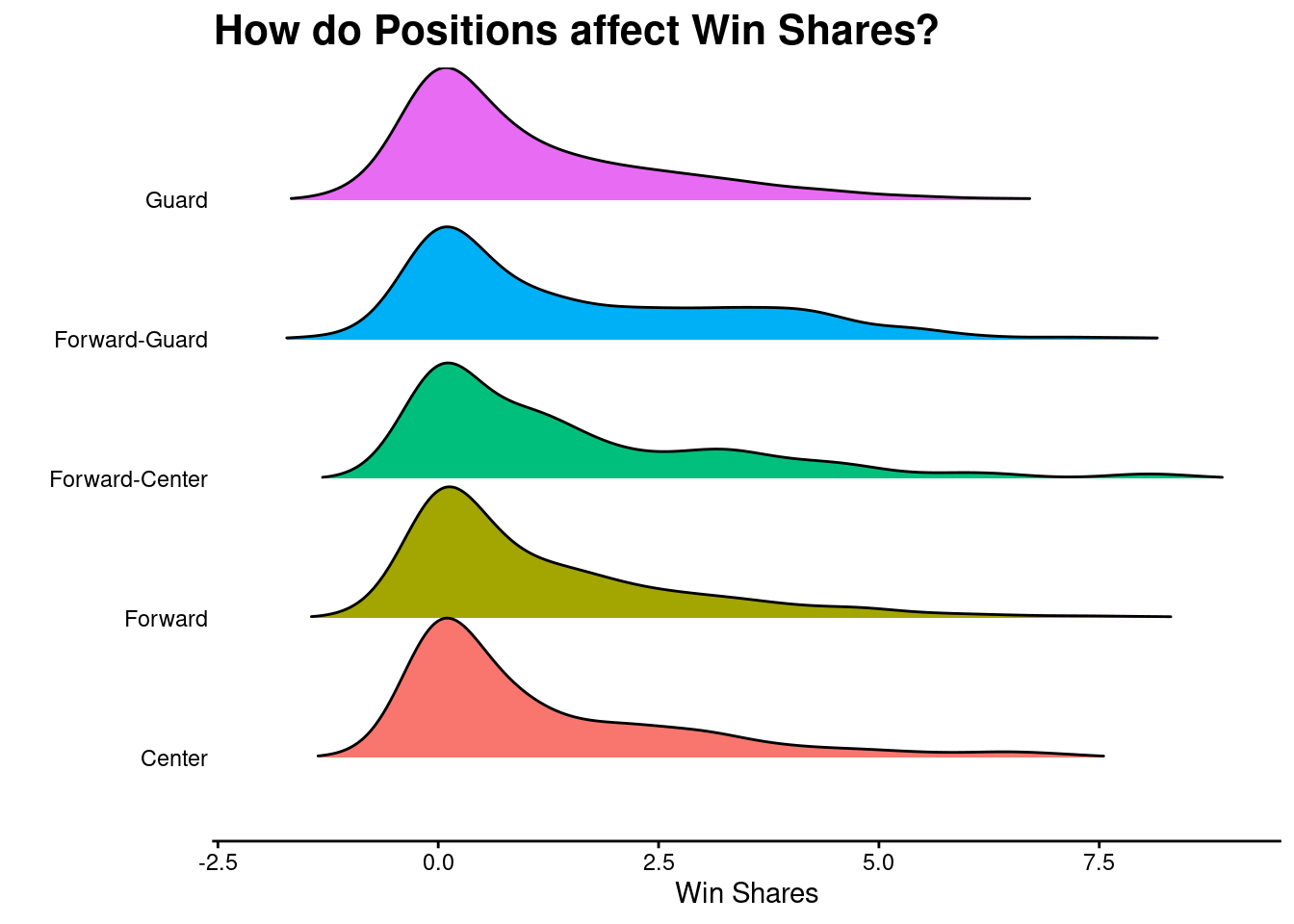
What we found was that all positions tend to have relatively similar effects on win shares…
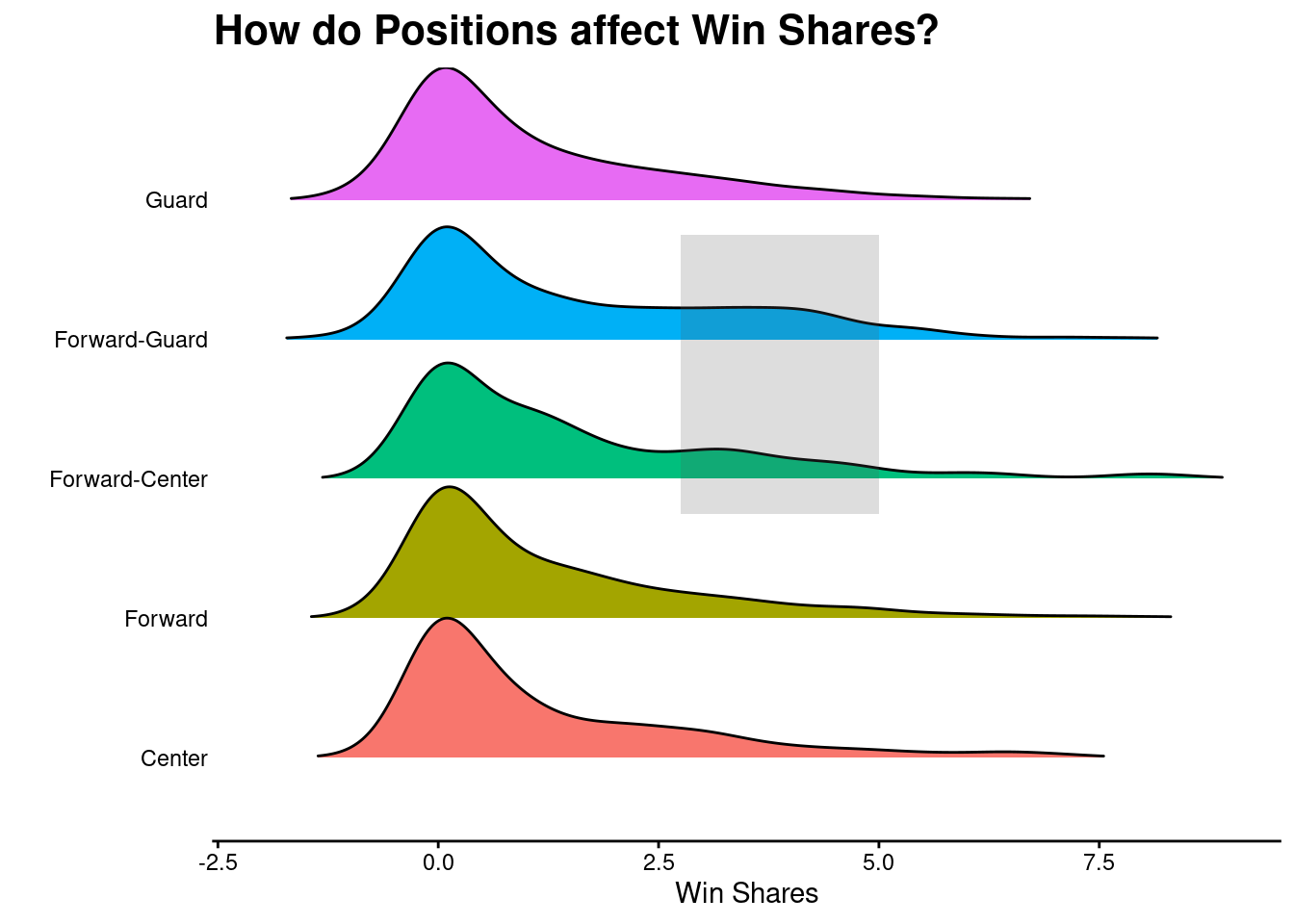
…however, players that can play multiple positions can also have higher win shares
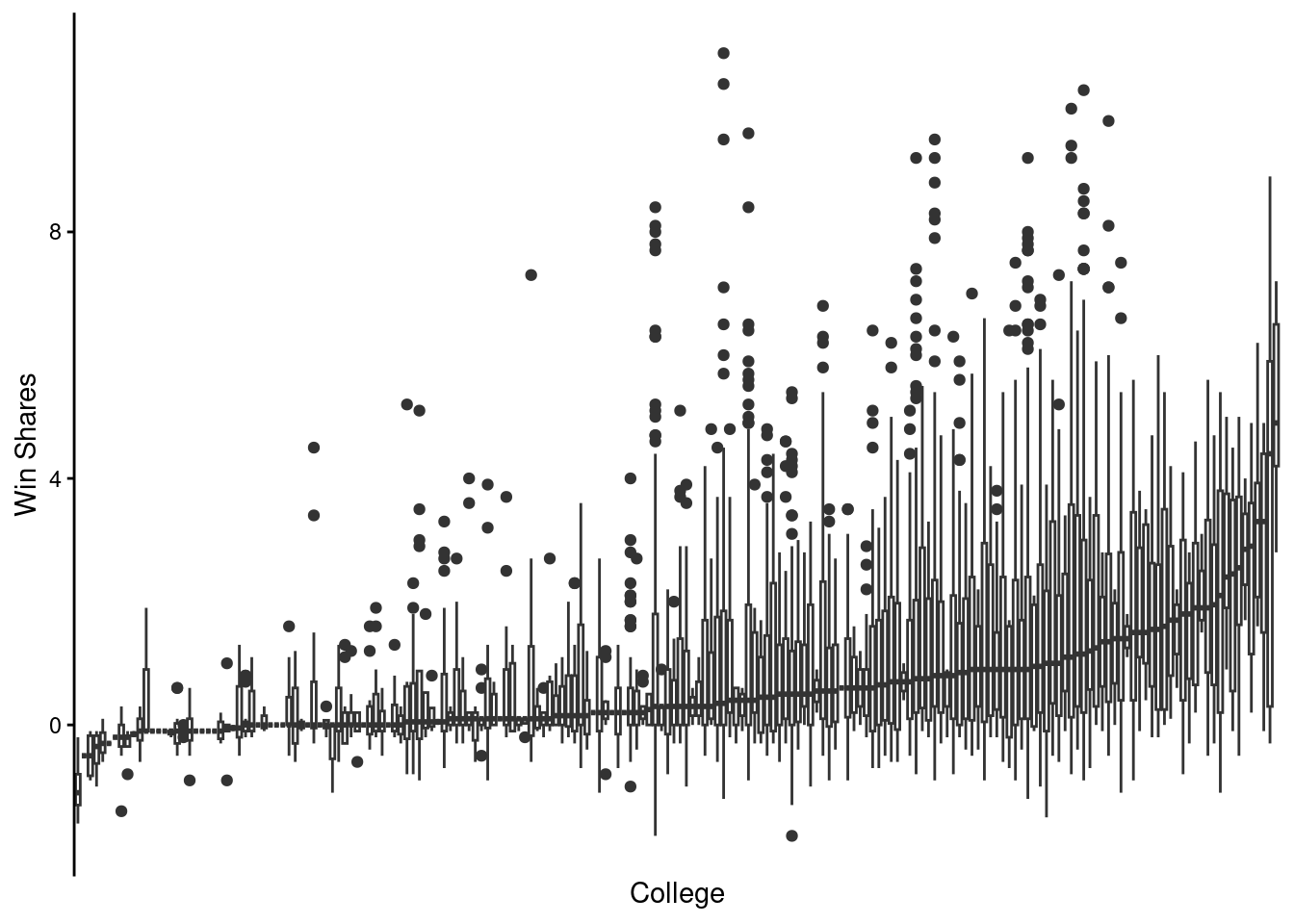
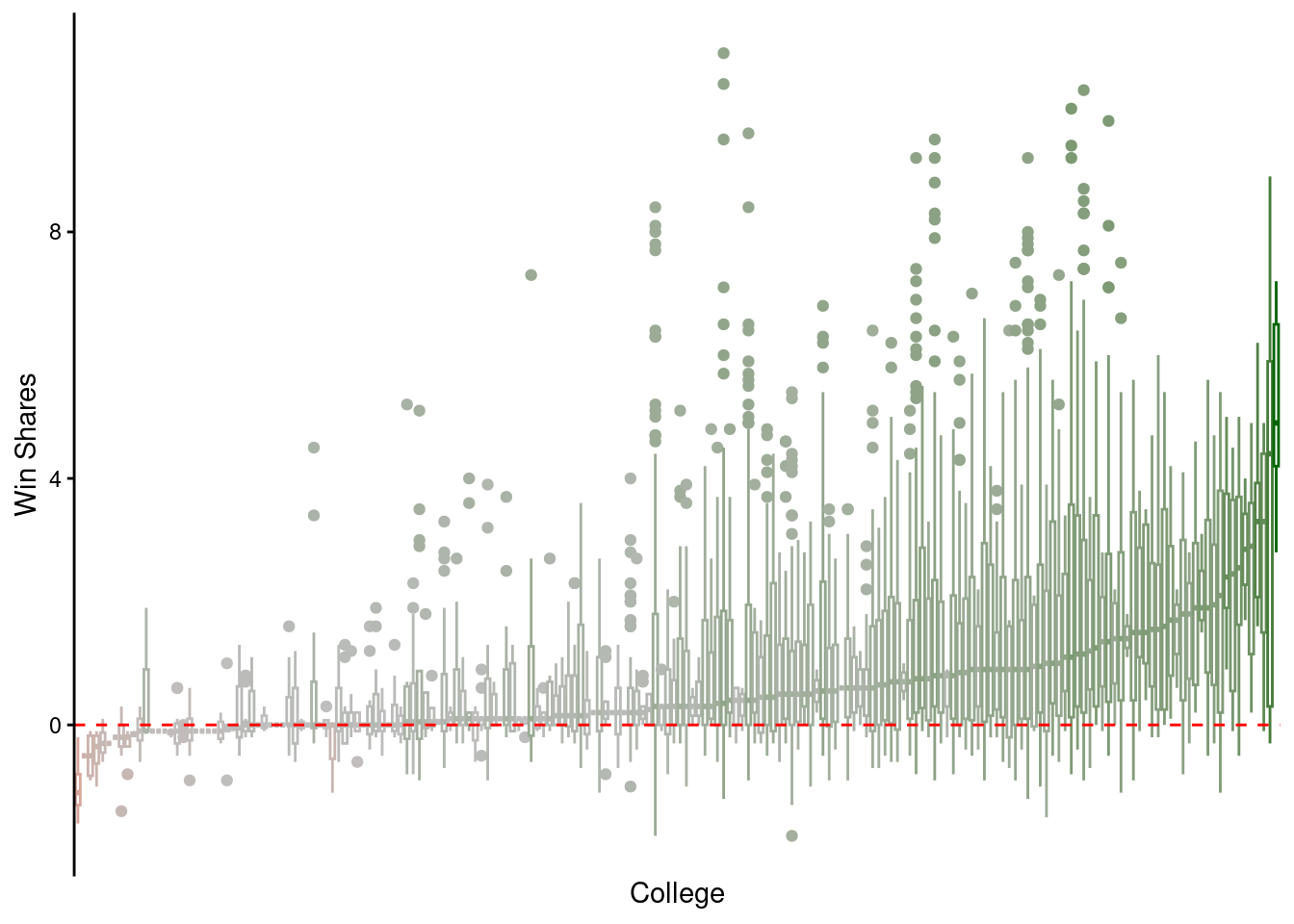
Perhaps there are specific schools that produce stellar players?
In fact, there are.
However, most school actually produce good players.
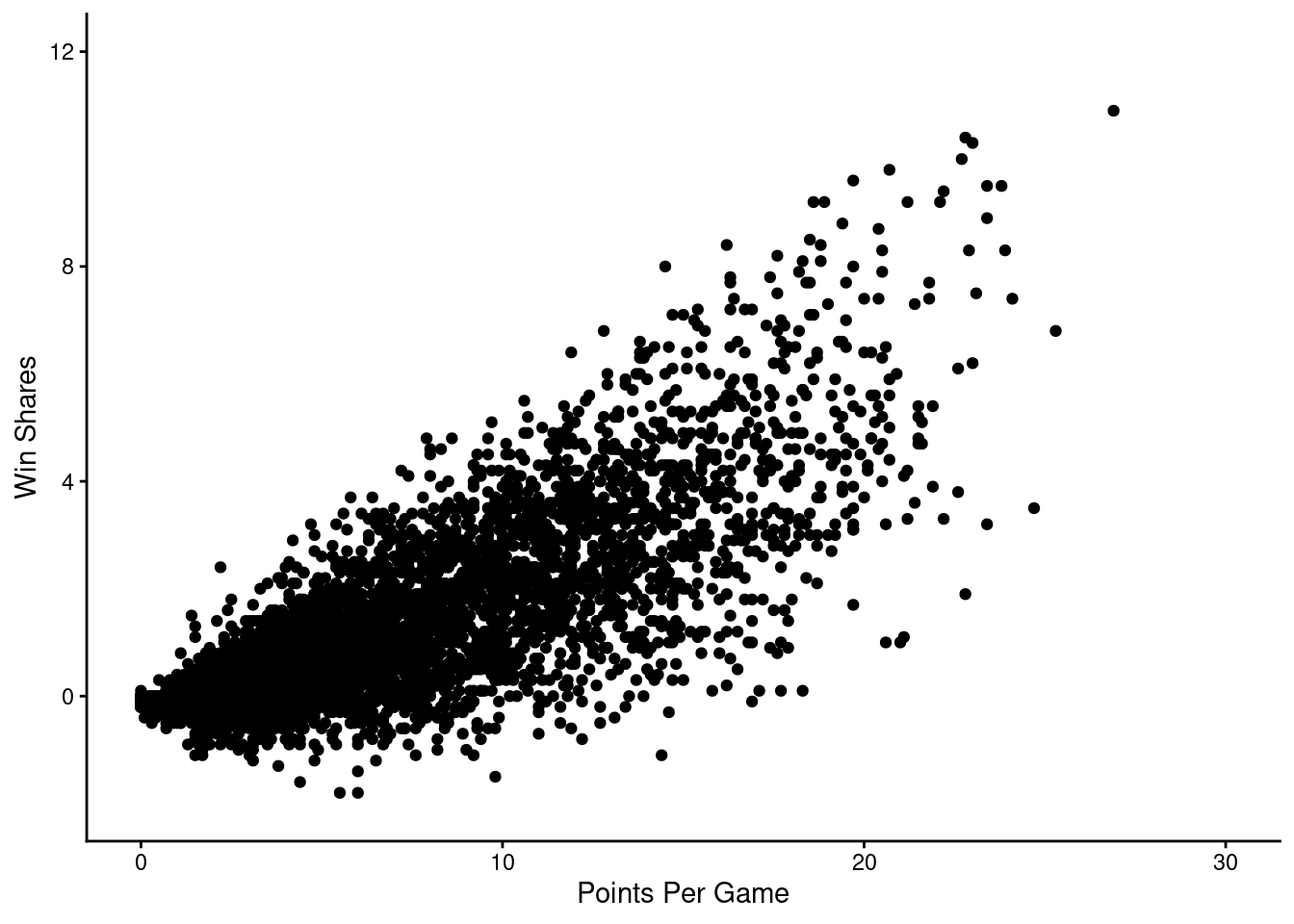
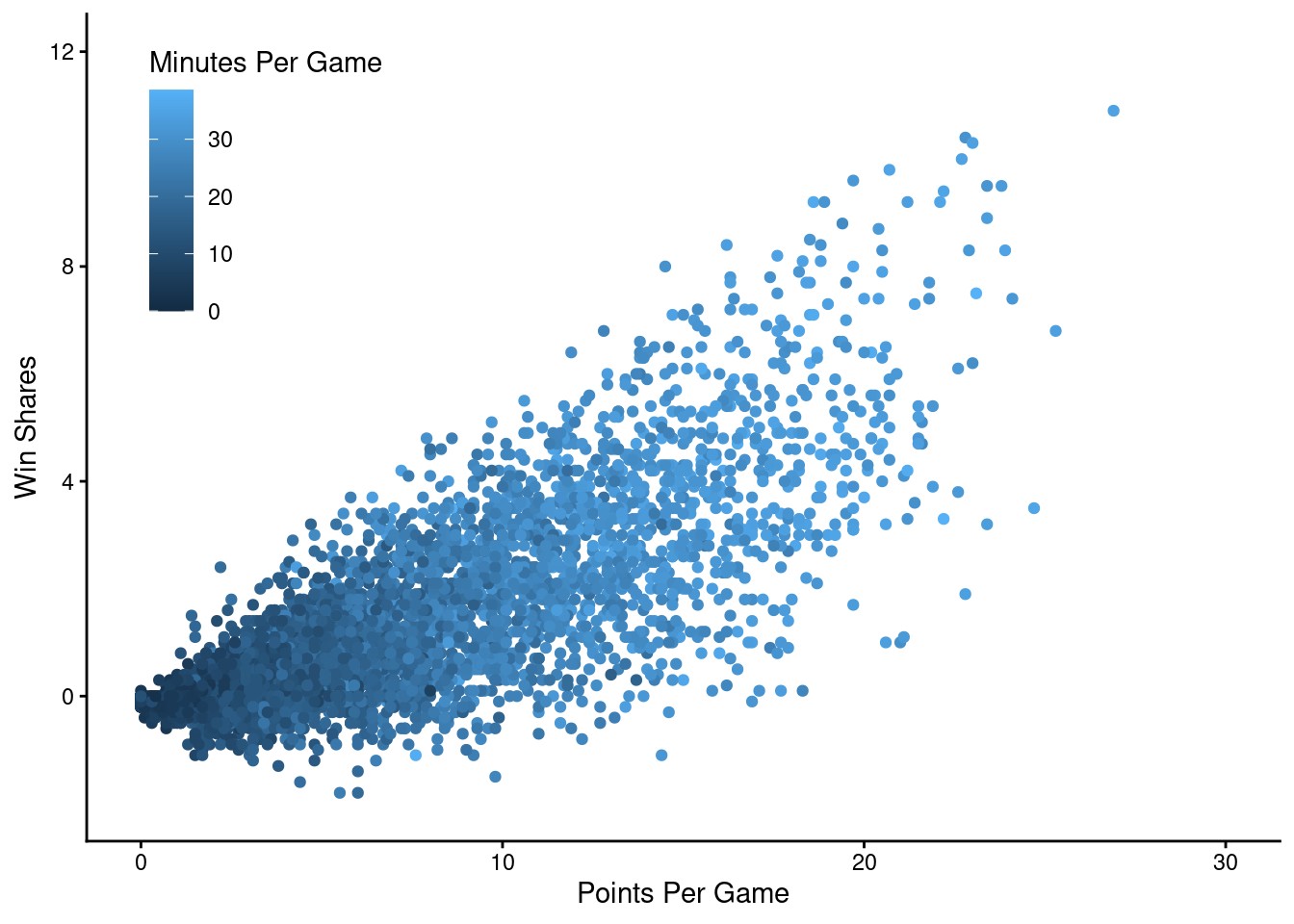
Based on intuition alone, we’d expect players that score more points to contribute the most to win shares.
That intuition turns out to be correct…
and closely related to minutes per game, where players that play longer tend to score more points (and vice versa), which improves a player’s Win Shares.
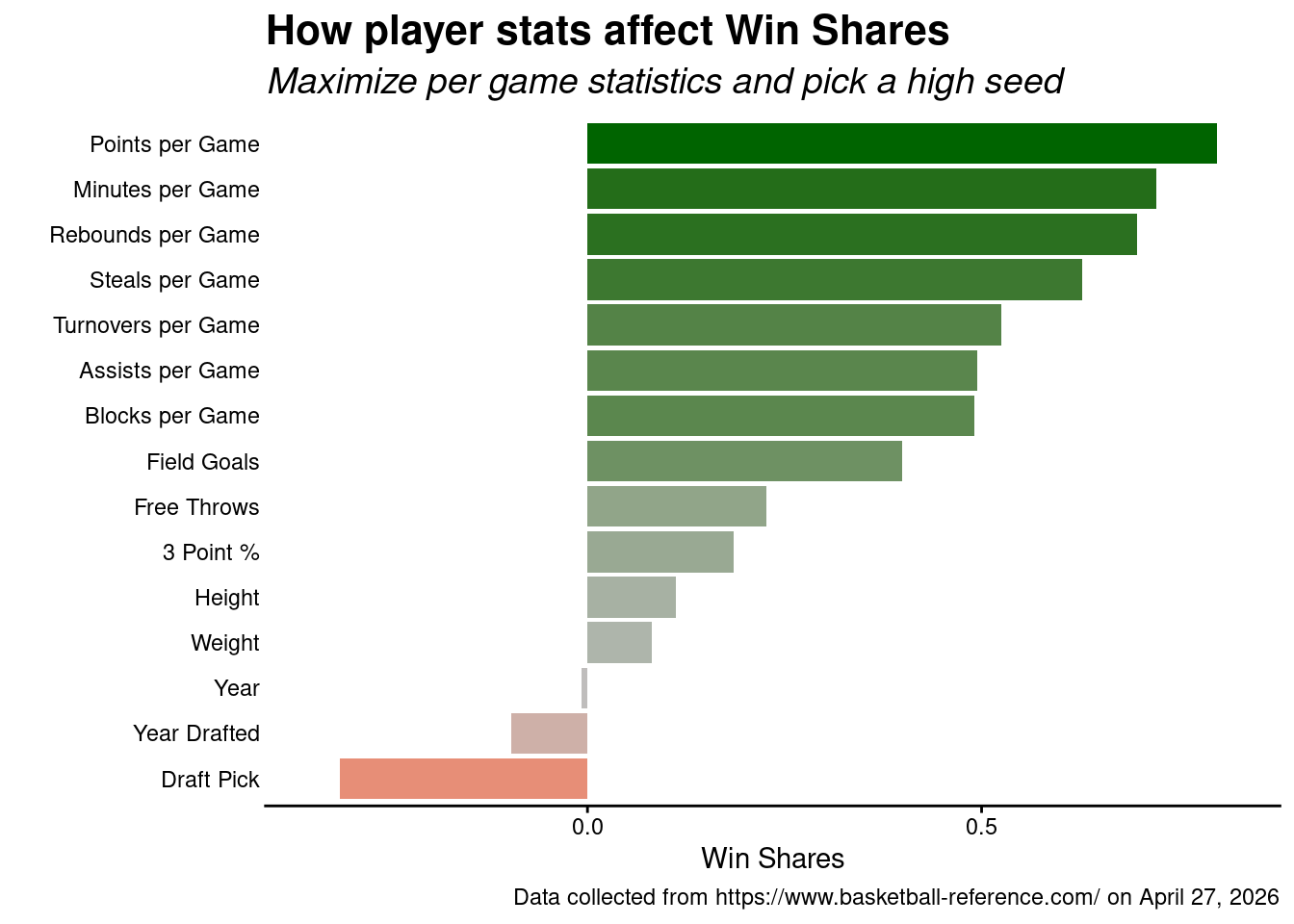
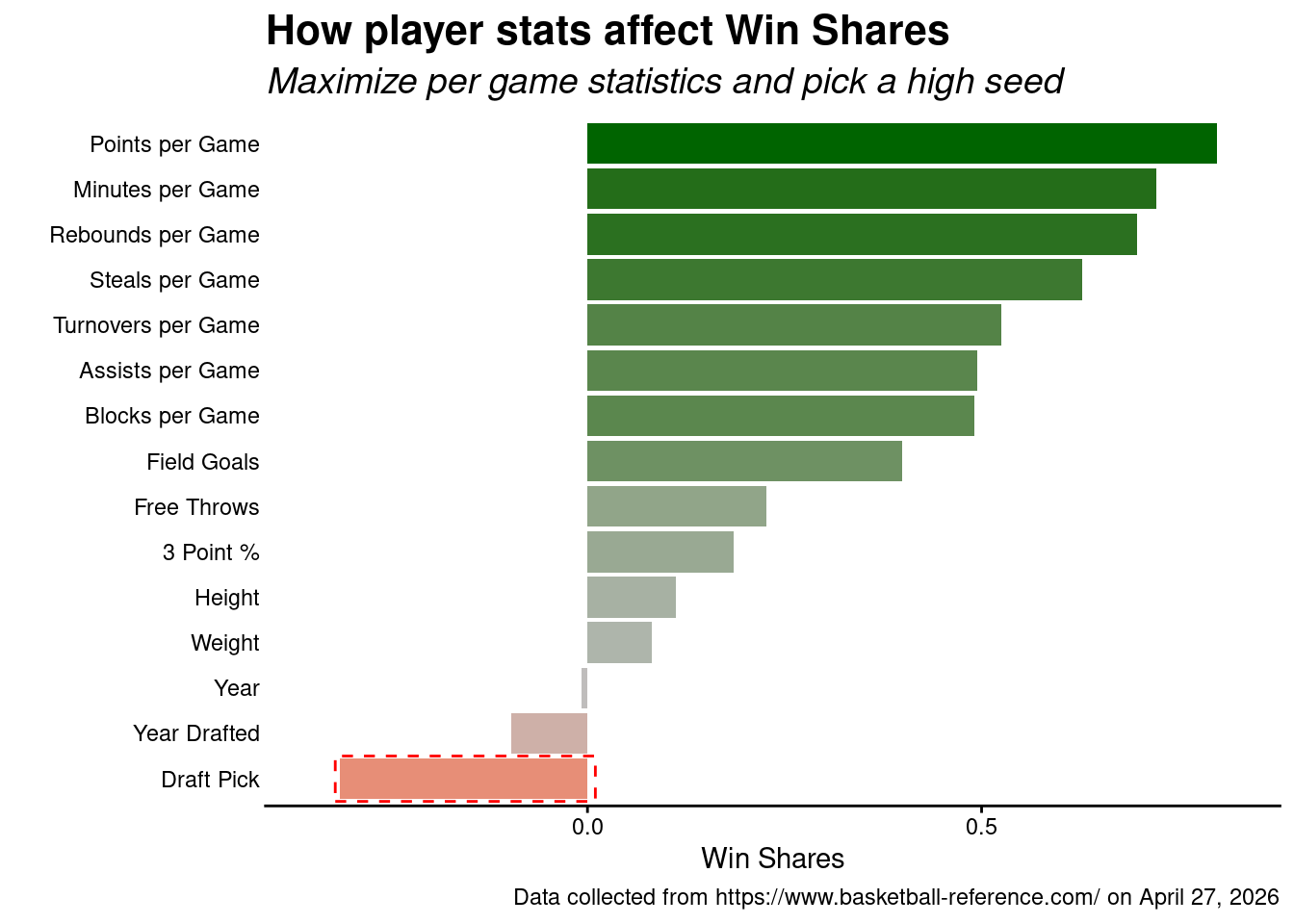
When we look at all numeric variables…
…we see that being proficent in nearly any of them would make you a more valuable player…
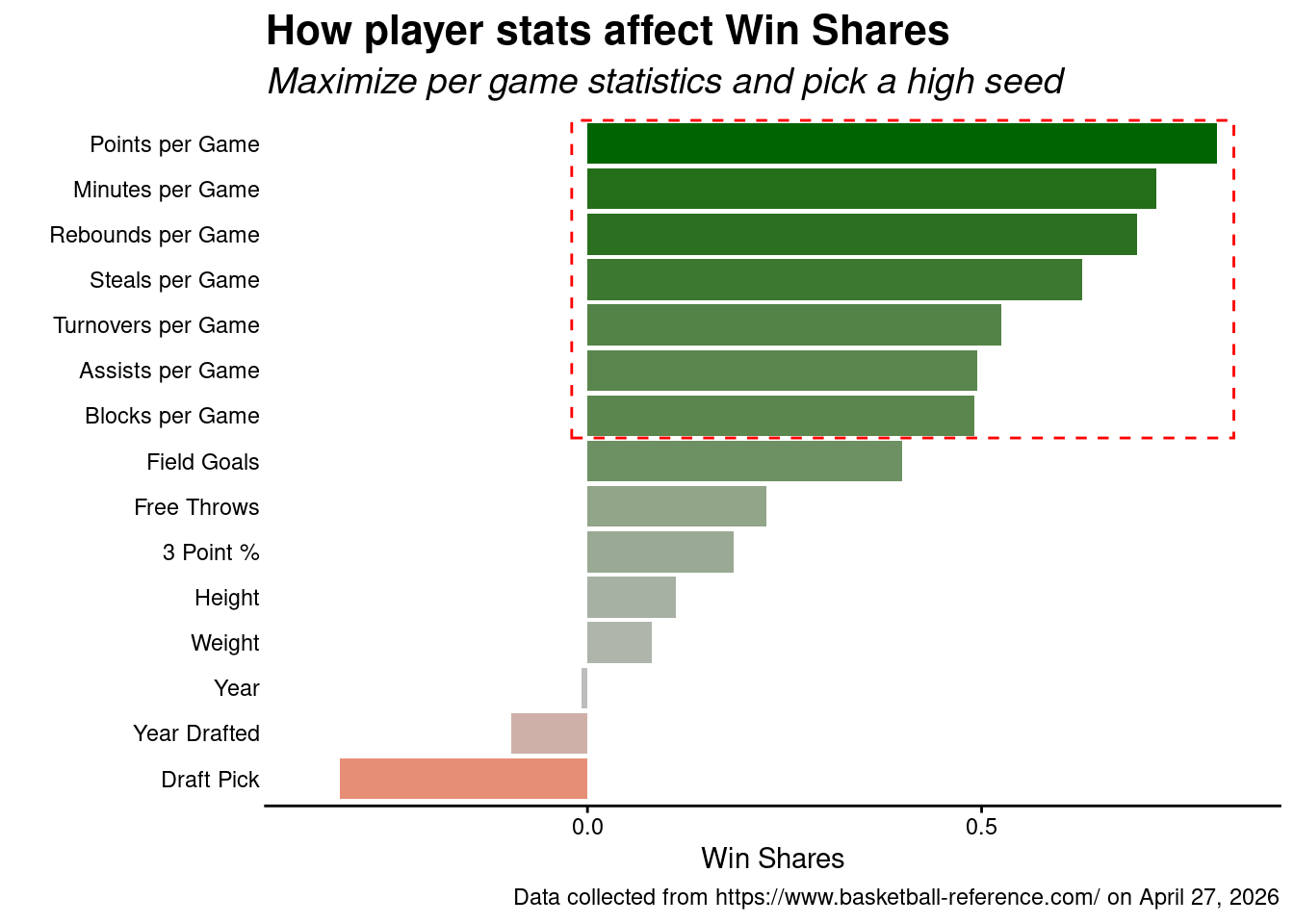
…however, players that can maximize their per-game statistics tend to be more valuable players on the court.
Additionally, if you can minimize your draft pick number – that it, be a number close to 1 (i.e., be first pick) – you tend to do well in terms of win shares.
Speaking of draft pick…
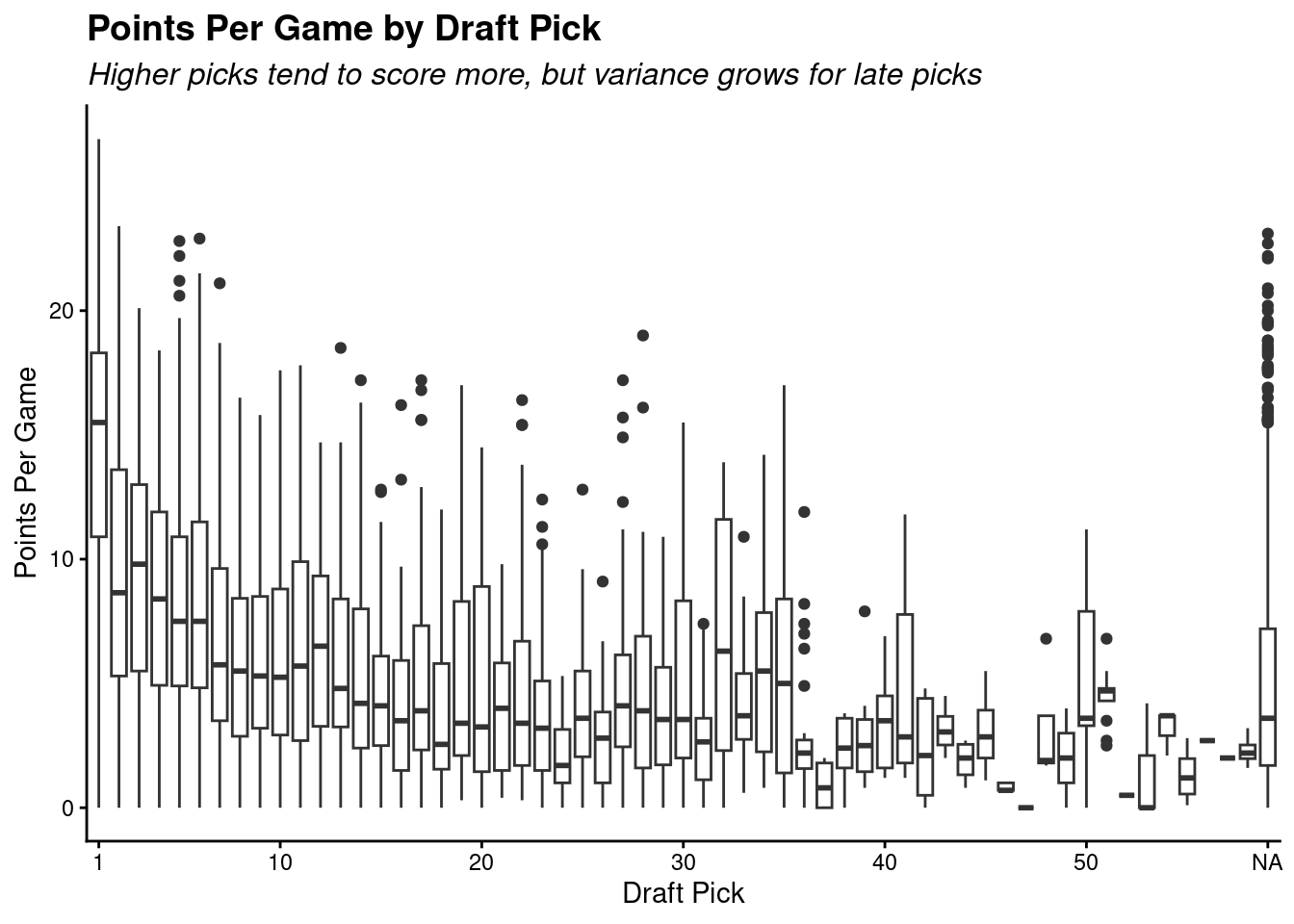
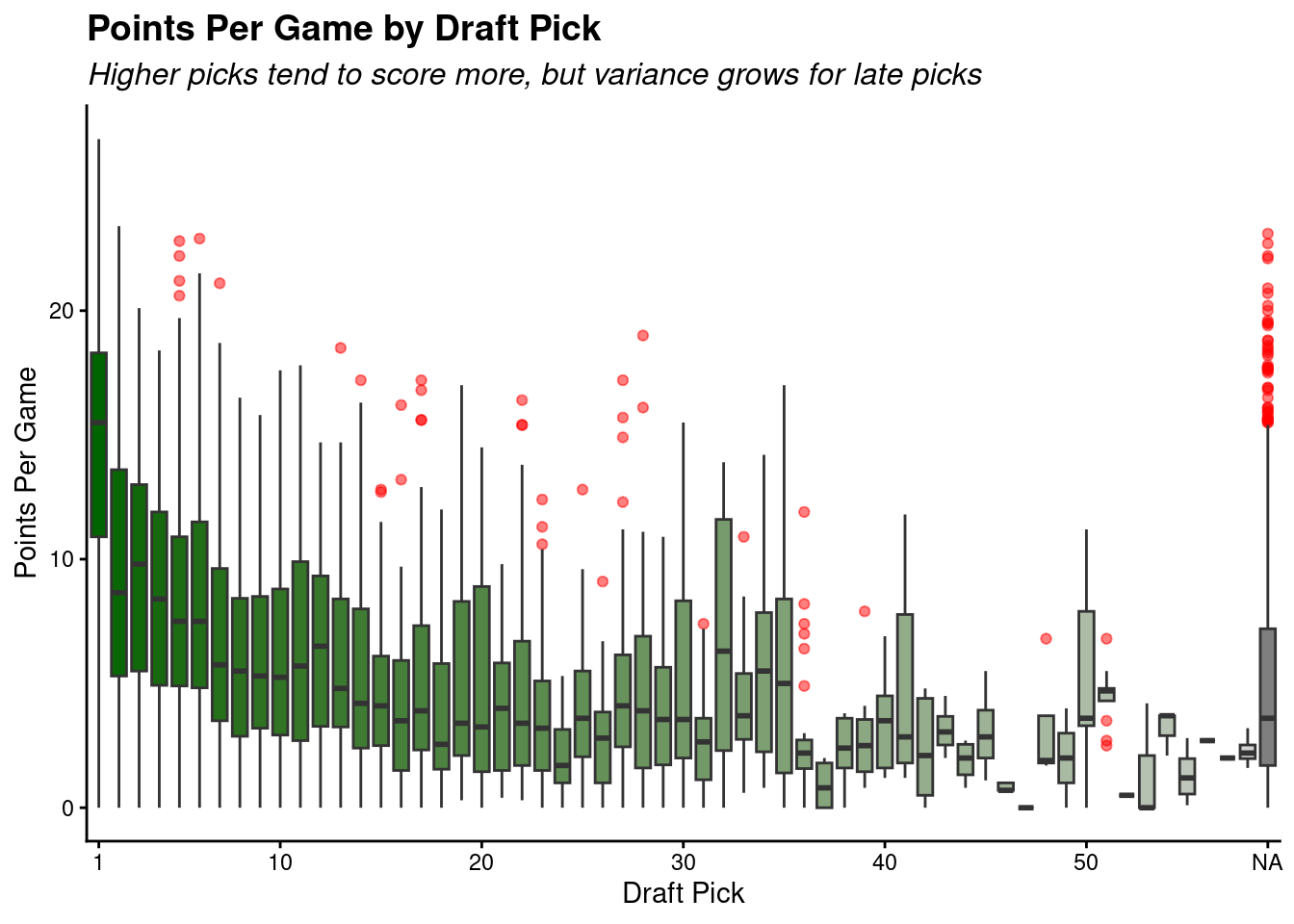
This graph illustrates the points-per-game scoring from each draft pick slot across all years of our dataset.
Higher picks score, on average, more points per game than players of lower draft slots. A notable difference is that the NA category is very widespread in its outcomes. This is due to undrafted free agents and international players who were not formally drafted, but were successful anyways.
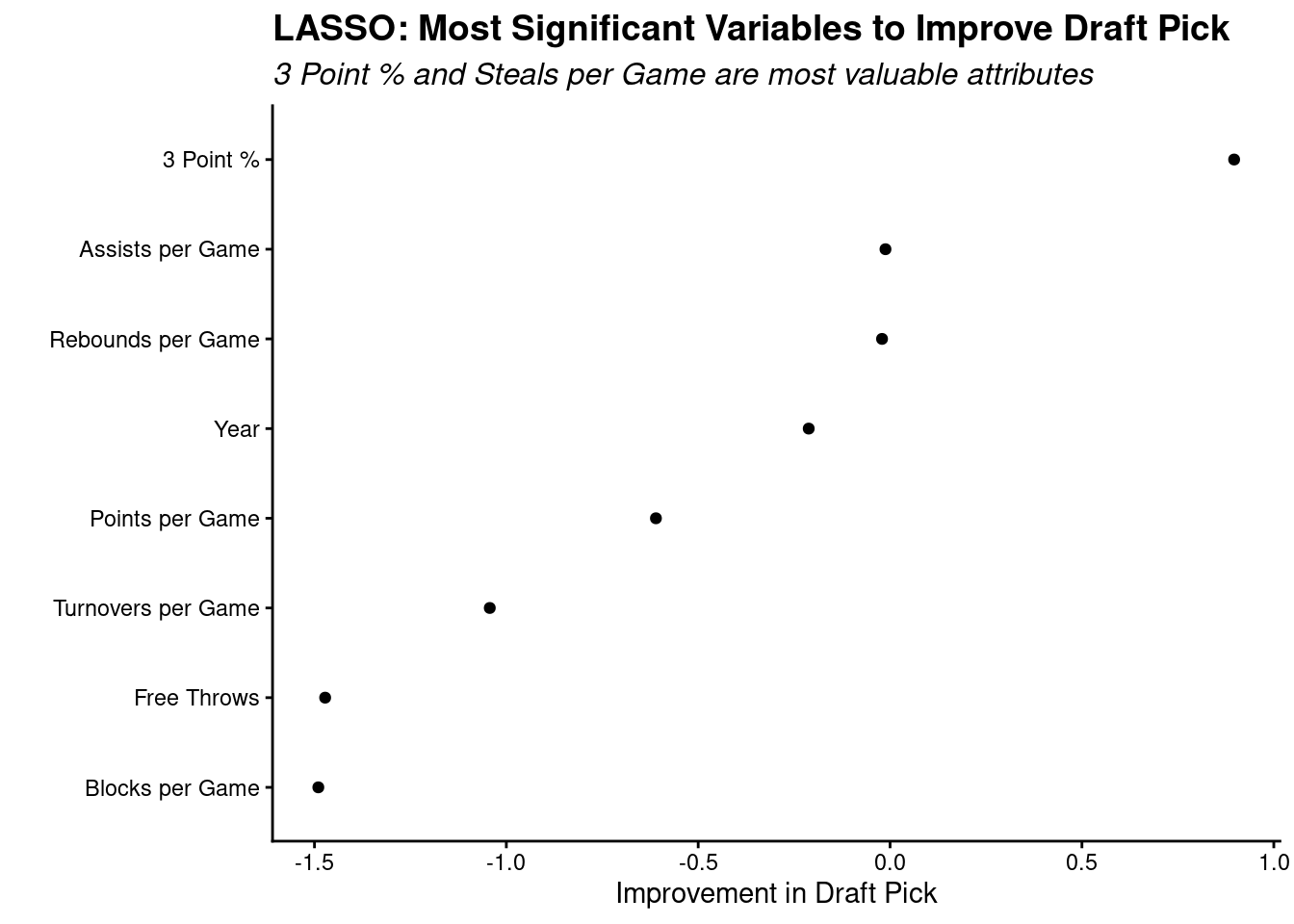
When we look at the most significant variables that effect a player’s draft pick, through a LASSO model…
…we see the percentage of 3-pointers is most important according to the LASSO model. Although still a variable to be considered, the free throws are not a meaningful variable to look at for draft selection.
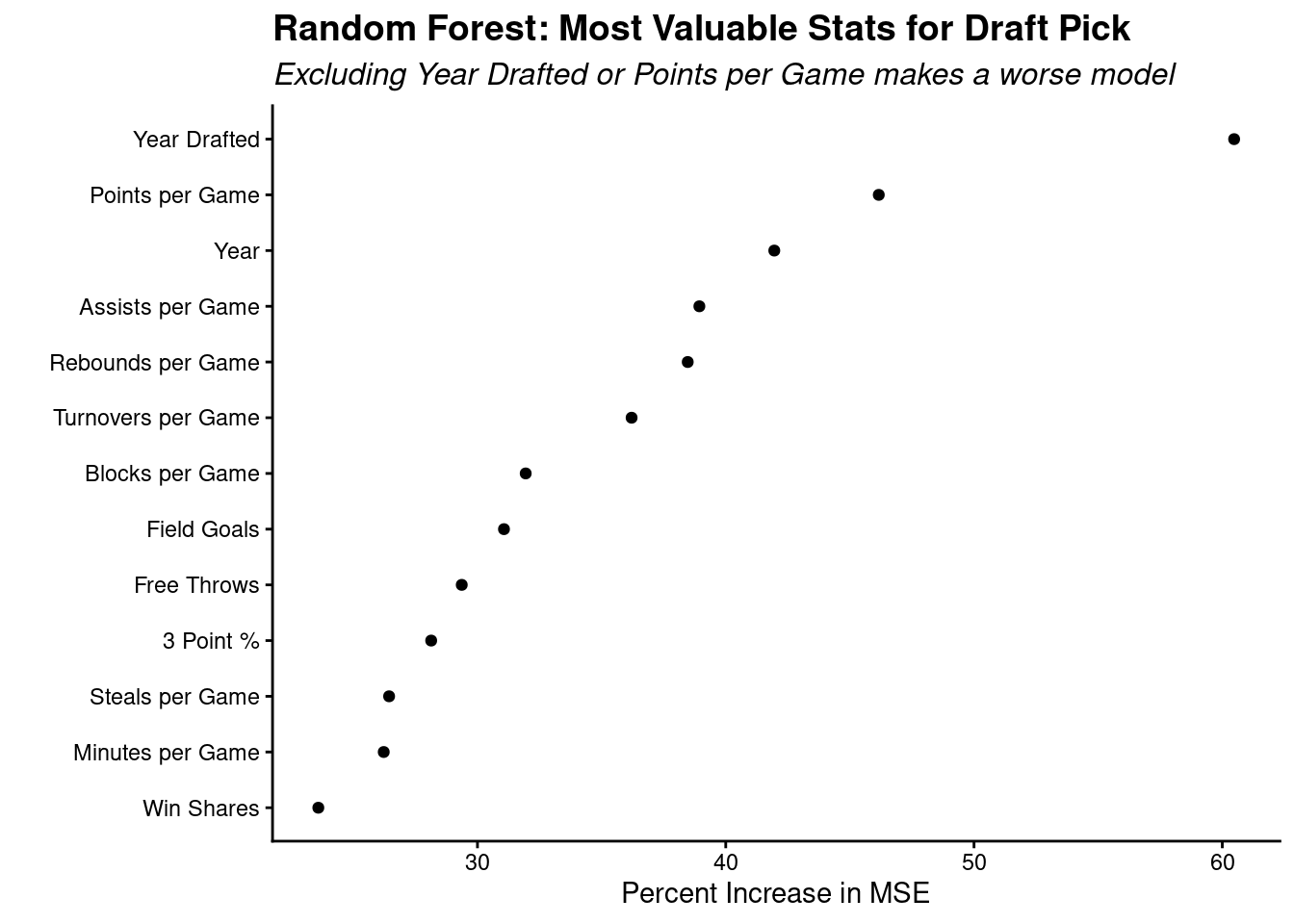
We also created a random forest to explore the relationship between variables related to drafting and the percentage error in picking the right player.
The percentage increase in MSE measures how much the prediction error increases if a variable is removed. The higher the MSE, the more important that variable is, such as points per game and assists per game, to name a few.
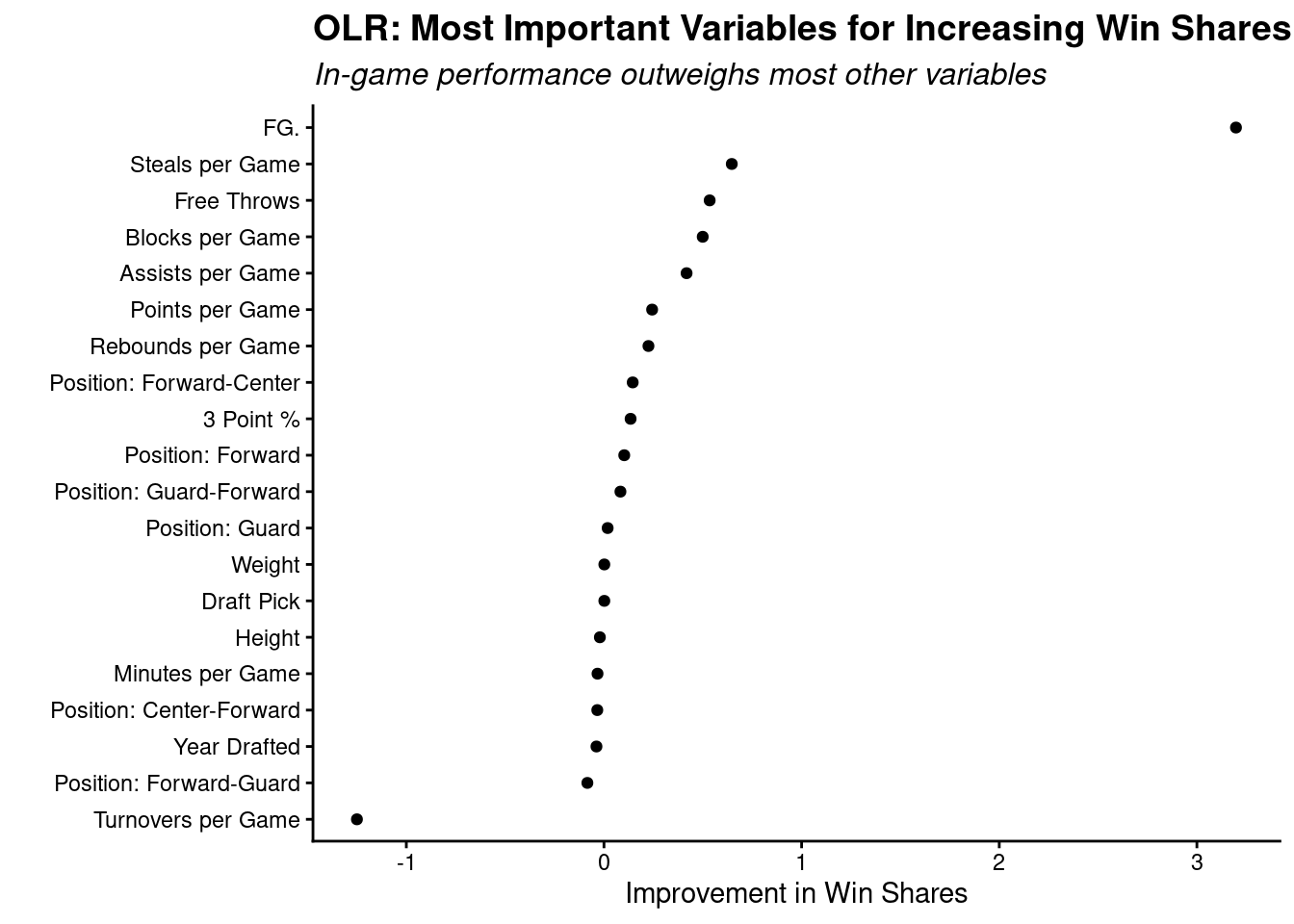
We also created an ordinary linear regression model (OLR) to explore relationships between various WNBA stats and Win Shares in more detail.
This plot illustrates the importance of different statistical categories in relation to win shares. The further to the right a category is, the better an improvement in that category does to a player’s win shares. Meaning, a one unit increase in a player’s field goal percentage has a dramatically positive effect on that player’s win shares. The inverse is true for turnovers per game.
Interpretations
According to the data that we collected, it appears that the pick that a player was selected at has an influence over the future success of that player. The player selected first overall tends to have an outsized level of success, with fewer wins generated by the 2nd through 6th picks. There is a drop of nearly two full win shares on average between first overall picks and those taken anywhere in the top six, and that gap continues to widen as selections move deeper into the draft. Players taken between seventh and fifteenth average just over one win share per season, while undrafted players who make a roster average just 0.6. The relationship is real but it is worth noting that it functions more as a proxy for talent level than as a causal mechanism. Being picked first does not make a player better; it reflects that evaluators already believed they were.
That said, draft position explains only about ten percent of the variation in win shares when modeled on its own alongside height and weight. Physical attributes, despite their intuitive appeal as predictors, turn out to have very limited standalone power. Height carries a small positive signal, taller players tend to accumulate more win shares in part because the center and forward positions naturally generate more rebounds and blocks, but weight adds almost nothing once height is accounted for. The physical model as a whole leaves ninety percent of the outcome unexplained.
The performance statistics model tells a far more complete story. Points per game, rebounds per game, assists per game, blocks per game, steals per game, field goal percentage and free throw percentage together explain roughly 74 percent of win shares variance in a standard linear model, and a random forest using the same inputs pushes that figure to 76 percent. Scoring volume is the single most important factor by a wide margin, accounting for nearly 64 percent of the random forest’s predictive power on its own. But shooting efficiency amplifies or diminishes that volume in ways that matter enormously. A player scoring fifteen points per game on 50 percent shooting generates substantially more value than the same volume on 38 percent.
The most counterintuitive finding is the role of turnovers. Of all the variables in the model, turnovers per game carry the largest negative coefficient, sitting at nearly negative one full win share per turnover per game. That means a single additional turnover per game costs a player roughly as much in win shares as a steal or an assist is worth in the positive direction. Players who protect the ball are quietly among the most valuable contributors in the league regardless of how prominently they appear in the box score.
Answer to Question
The answer to the original question is that on-court production is what drives success in the WNBA, and the specific combination of scoring efficiently, distributing the ball, defending actively and limiting turnovers separates the most impactful players from the rest. Physical size and draft pedigree provide a foundation, but they account for a small fraction of what determines how much a player actually contributes once the game is being played. The five players with the highest career win shares in our dataset, Tamika Catchings, Nneka Ogwumike, Diana Taurasi, Sylvia Fowles and Lauren Jackson, all share one characteristic above any other. They were relentless producers who made good decisions with the ball, and they did it consistently across many seasons.
Source Code
---css: style/custom.cssformat: closeread-html: code-tools: true cr-style: narrative-background-color-overlay: "white" narrative-background-color-sidebar: "white" section-background-color: "white" narrative-text-color-overlay: "#182825" backgroundcolor: "white"---:::{.custom-title}What factors influence [success]{.highlight} in a WNBA player?:::```{r, echo=FALSE, include=FALSE}library(tidyverse)library(ggridges)library(corrr)library(broom)library(randomForest)library(glmnet)df <- read.csv("data/processed/WNBA_Stats_1997_2026.csv") %>% mutate(Draft.Pick = as.numeric(if_else(Draft.Pick == "Undrafted", NA, Draft.Pick))) %>% mutate(Height = as.numeric(str_extract(Height, "^\\d+")) * 12 + as.numeric(str_extract(Height, "(?<=-)\\d+")), Weight = as.numeric(str_remove(Weight, "lb")))wnba2 <- read.csv("./data/processed/WNBA_Stats_1997_2026.csv")```{.image}:::{.centered-text}Before we answer that question, let's go over some motivation.::::::{.centered-text}## MotivationThe WNBA Draft is an annual event in which teams select eligible college players and international prospects to join the league, shaping the next generation of professional women’s basketball talent. Similar to other professional sports drafts, selection order is largely determined by the previous season’s standings, with weaker teams given higher picks in an effort to maintain competitive balance. For general managers, the draft represents a critical decision point: players are evaluated not only on traditional box-score statistics such as points, rebounds, and assists, but also on efficiency measures, defensive contributions, and advanced indicators of value like win shares.In this analysis, we treat the draft as a decision problem where the goal is to identify players who are likely to provide the greatest overall impact at the professional level. Using available collegiate and pre-draft performance metrics—including per-game production, shooting efficiency (field goal, three-point, and free throw percentages), and all-around contributions such as steals, blocks, and turnovers—we aim to build a data-driven framework for player selection. This approach allows us to move beyond draft position alone and systematically compare prospects based on their statistical profiles and projected value to a WNBA roster.... so why the WNBA?```{r, echo=FALSE, include=TRUE, .scale-to-fill}league.df <- tibble( league = c("NBA", "WNBA"), revenue = c(14.3e9, 500e6), avg.salary = c(10.54e6, 583000), avg.ticket.price = c(228.50, 173.00), highest.paid.player = c(59606817,1.4e6), avg.viewership = c(1.8e6, 1.3e6), avg.attendance = c(18147, 11000), )annot.df <- league.df %>% select(league, avg.attendance)league.df %>% pivot_longer(cols = !league, names_to = "variable") %>% ggplot(aes(x = variable, y = value, fill = league)) + geom_col() + geom_text( aes(label = if_else( variable %in% c("avg.attendance", "avg.viewership"), str_c(scales::comma(value), " people"), scales::dollar(value, accuracy = 1))), position = position_stack(vjust = 0.5), size = 3.5, fontface = "italic", ) + scale_fill_manual(values = c( "NBA" = "#DADEDF", "WNBA" = "#FFA62B" )) + facet_wrap( ~variable, scales = "free", strip.position = "top", labeller = labeller(variable = c( avg.attendance = "Attendance", avg.salary = "Salary", avg.ticket.price = "Ticket Price", avg.viewership = "Viewership", highest.paid.player = "Highest-Paid Player", revenue = "Revenue" )) ) + labs(title = "WNBA vs NBA: Comparison by the Numbers", subtitle = "Almost every WNBA stat has more than doubled in the last 2 years ", fill = "", caption = "Figure created using data from https://www.wsn.com/nba/nba-vs-wnba/ last updated April 22, 2026.") + theme_classic() + theme( axis.title.x = element_blank(), axis.title.y = element_blank(), axis.ticks.x = element_blank(), axis.text.x = element_blank(), axis.line.x = element_blank(), axis.text.y = element_blank(), axis.line.y = element_blank(), axis.ticks.y = element_blank(), strip.background = element_blank(), legend.position = "left", strip.text = element_text(face = "bold", size = 12), plot.title = element_text(face = "bold", size = 16), plot.subtitle = element_text(face = "italic", size = 14) )```We wanted to understand what factors contribute to a WNBA player succeeding in the league. Given that the WNBA is a newer and more developing league, trends are not as established as they are in the NBA. Does height play a bigger role than weight? Does being selected early in the draft guarantee a more productive career? These are the kinds of questions that motivated us to look more closely at the data the league has generated over its nearly three decades of existence.This brings us to our research question:::::::{.custom-title}What factors influence the success of a WNBA player?::::::{.centered-text}## Data:::::::{.cr-section}To answer that question, we assembled a dataset covering every player season recorded in the WNBA from **1997 to 2025** @cr-1997-2025drawing from **Basketball Reference** as our primary source. @cr-basketball-reference| {#cr-1997-2025 .scale-to-fill}| 1997-2025:::{#cr-basketball-reference .scale-to-fill}::::::::::{.cr-section}The final dataset contains @cr-players| {#cr-players .scale-to-fill}| **1,011** unique playersacross @cr-player-seasons| {#cr-player-seasons .scale-to-fill}| **4,828** player seasonsfiltered to players with at least five minutes per game.:::::::{.cr-section}Each observation captures the following player statistics: @cr-list :::{#cr-list .scale-to-fill}**Player Statistics*** year* position* team* university* country of origin* draft year* draft pick* height* weight:::in addition to **per game statistics** like: @cr-list2:::{#cr-list2 .scale-to-fill}**Per Game Statistics*** points* rebounds* assists* blocks* steals* turnovers* shooting percentages :::as well as our predictor variable: @cr-win-shares| {#cr-win-shares .scale-to-fill}| **Win Shares**`Win shares` is a single number that attempts to credit each player with a portion of their team's wins based on both their offensive and defensive contributions. A player averaging around 1.3 win shares in a season is performing near the league median. A player generating 5 or more in a season is among the most impactful in the league that year.::::To explore the data visually, we examined how win shares are distributed across the full dataset, how they vary by position and era, and how individual statistics relate to overall contributions. We built several regression models ranging from a standard OLS regression on performance statistics, to a physical attributes only model, to a combined model, and finally a random forest to capture nonlinear structure and rank feature importance across all predictors simultaneously.:::{.centered-text}## Results:::::::{.cr-section}One thing we looked at was player positions. Specifically, how player position was related to a player's win shares. @cr-position-blank:::{#cr-position-blank}```{r, echo=FALSE}ws_range <- range(df$Win.Shares, na.rm = TRUE)pos_range <- range(df$Position, na.rm = TRUE)# does one position attribute to winning more than others?df %>% mutate(Position = case_when( Position == "G-F" ~ "F-G", Position == "C-F" ~ "F-C", TRUE ~ Position )) %>% ggplot(aes(x = Win.Shares, y = Position, fill = Position)) + geom_density_ridges( alpha = 0, # fully transparent color = NA, # no outline scale = 1, rel_min_height = 0.01 ) + xlim(-2, 9) + theme_classic() + labs(x = "Win Shares", y = "", title = "How do Positions affect Win Shares?") + scale_y_discrete(labels = c( `G-F` = "Guard-Forward", G = "Guard", `F-G` = "Forward-Guard", `F-C` = "Forward-Center", F = "Forward", `C-F` = "Center-Forward", C = "Center" )) + theme( strip.background = element_blank(), axis.line.y = element_blank(), axis.ticks.y = element_blank(), legend.position = "none", strip.text = element_text(face = "bold", size = 12), plot.title = element_text(face = "bold", size = 16), plot.subtitle = element_text(face = "italic", size = 14) )```:::What we found was that **all positions tend to have relatively similar effects on win shares**... @cr-position-filled:::{#cr-position-filled}```{r, echo=FALSE, include=TRUE}# does one position attribute to winning more than others?df %>% mutate(Position = case_when( Position == "G-F" ~ "F-G", Position == "C-F" ~ "F-C", TRUE ~ Position )) %>% ggplot(aes(x = Win.Shares, y = Position, fill = Position)) + geom_density_ridges(scale = 1, rel_min_height = 0.01) + xlim(-2, 9) + theme_classic() + labs(x = "Win Shares", y = "", title = "How do Positions affect Win Shares?") + scale_y_discrete(labels = c( `G-F` = "Guard-Forward", G = "Guard", `F-G` = "Forward-Guard", `F-C` = "Forward-Center", F = "Forward", `C-F` = "Center-Forward", C = "Center" )) + theme( strip.background = element_blank(), axis.line.y = element_blank(), axis.ticks.y = element_blank(), legend.position = "none", strip.text = element_text(face = "bold", size = 12), plot.title = element_text(face = "bold", size = 16), plot.subtitle = element_text(face = "italic", size = 14) )```:::...however, **players that can play multiple positions can also have higher win shares** @cr-position-annotate:::{#cr-position-annotate}```{r, echo=FALSE, include=TRUE}# does one position attribute to winning more than others?df %>% mutate(Position = case_when( Position == "G-F" ~ "F-G", Position == "C-F" ~ "F-C", TRUE ~ Position )) %>% ggplot(aes(x = Win.Shares, y = Position, fill = Position)) + geom_density_ridges(scale = 1, rel_min_height = 0.01) + annotate("rect", xmin = 2.75, xmax = 5, ymin = 2.75, ymax = 4.75, alpha = 0.2) + xlim(-2, 9) + theme_classic() + labs(x = "Win Shares", y = "", title = "How do Positions affect Win Shares?") + scale_y_discrete(labels = c( `G-F` = "Guard-Forward", G = "Guard", `F-G` = "Forward-Guard", `F-C` = "Forward-Center", F = "Forward", `C-F` = "Center-Forward", C = "Center" )) + theme( strip.background = element_blank(), axis.line.y = element_blank(), axis.ticks.y = element_blank(), legend.position = "none", strip.text = element_text(face = "bold", size = 12), plot.title = element_text(face = "bold", size = 16), plot.subtitle = element_text(face = "italic", size = 14) )```:::::::::::{.cr-section}Perhaps there are specific schools that produce stellar players? @cr-college-blank:::{#cr-college-blank}```{r, echo=FALSE, include=TRUE}# do any schools do a good job at producing winners?summary_df <- df %>% group_by(College...Origin) %>% summarize(med.ws = median(Win.Shares, na.rm = TRUE)) %>% arrange(desc(med.ws)) %>% mutate(rank = row_number())label_df <- summary_df %>% filter(rank <= 3 | rank > n() - 2) %>% mutate( label_y = med.ws + 1.5 # adjust offset as needed )df %>% ggplot(aes(x = fct_reorder(College...Origin, Win.Shares), y = Win.Shares)) + labs(x = "College", y = "Win Shares") + theme_classic() + theme( axis.text.x = element_blank(), axis.ticks.x = element_blank(), axis.line.x = element_blank() )```:::In fact, there are. @cr-college-filled:::{#cr-college-filled}```{r, echo=FALSE, include=TRUE}df %>% ggplot(aes(x = fct_reorder(College...Origin, Win.Shares), y = Win.Shares)) + geom_boxplot() + labs(x = "College", y = "Win Shares") + theme_classic() + theme( axis.text.x = element_blank(), axis.ticks.x = element_blank(), axis.line.x = element_blank() )```:::However, most school actually produce good players. @cr-college-annotated:::{#cr-college-annotated}```{r, echo=FALSE, include=TRUE}college_avg <- df %>% group_by(College...Origin) %>% summarize(avg_ws = mean(Win.Shares, na.rm = TRUE))df %>% left_join(college_avg, by = "College...Origin") %>% ggplot(aes(x = fct_reorder(College...Origin, Win.Shares), y = Win.Shares, color= avg_ws)) + geom_boxplot() + scale_color_gradient2(low = "red", mid = "grey", high = "dark green", midpoint = 0) + geom_hline(yintercept = 0, color = "red", linetype = "dashed") + labs(x = "College", y = "Win Shares") + theme_classic() + theme( axis.text.x = element_blank(), axis.ticks.x = element_blank(), axis.line.x = element_blank(), legend.position = "none" )```:::::::::::{.cr-section}Based on intuition alone, we'd expect players that score more points to contribute the most to win shares. @cr-points-blank:::{#cr-points-blank}```{r, echo=FALSE, include=TRUE}df %>% ggplot(aes(x = Points.Per.Game, y = Win.Shares, color = Minutes.Per.Game)) + xlim(0, 30) + ylim(-2, 12) + labs(x = "Points Per Game", y = "Win Shares", color = "Minutes Per Game") + theme_classic() + theme( legend.position = "none" )```:::That intuition turns out to be correct... @cr-points-filled:::{#cr-points-filled}```{r, echo=FALSE, include=TRUE}df %>% ggplot(aes(x = Points.Per.Game, y = Win.Shares)) + geom_point() + xlim(0, 30) + ylim(-2, 12) + labs(x = "Points Per Game", y = "Win Shares", color = "Minutes Per Game") + theme_classic() + theme( legend.position = "none" )```:::and closely related to minutes per game, where players that play longer tend to score more points (and vice versa), which improves a player's Win Shares. @cr-points-colored:::{#cr-points-colored}```{r, echo=FALSE, include=TRUE}df %>% ggplot(aes(x = Points.Per.Game, y = Win.Shares, color = Minutes.Per.Game)) + geom_point() + xlim(0, 30) + ylim(-2, 12) + labs(x = "Points Per Game", y = "Win Shares", color = "Minutes Per Game") + theme_classic() + theme( legend.position = c(0.15, 0.8) )```:::::::::::{.cr-section}When we look at all numeric variables... @cr-svw-blank:::{#cr-svw-blank}```{r, echo=FALSE, include=TRUE}win.shares.cor <- df %>% correlate() %>% focus(Win.Shares)win.shares.cor %>% ggplot(aes(y = fct_reorder(term, Win.Shares), x = Win.Shares, fill = Win.Shares)) + scale_fill_gradient2( low = "red", # negative mid = "grey", # zero high = "dark green", # positive midpoint = 0 ) + labs(x = "Win Shares", y = "", title = "How player stats affect Win Shares", subtitle = "Maximize per game statistics and pick a high seed", caption = "Data collected from https://www.basketball-reference.com/ on April 27, 2026") + scale_y_discrete(labels = c( FG. = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game" )) + xlim(-0.35, 0.82) + theme_classic() + theme( axis.line.y = element_blank(), axis.ticks.y = element_blank(), strip.background = element_blank(), legend.position = "none", strip.text = element_text(face = "bold", size = 12), plot.title = element_text(face = "bold", size = 16), plot.subtitle = element_text(face = "italic", size = 14) )```:::...we see that being proficent in nearly any of them would make you a more valuable player... @cr-svw-filled:::{#cr-svw-filled}```{r, echo=FALSE, include=TRUE}win.shares.cor %>% ggplot(aes(y = fct_reorder(term, Win.Shares), x = Win.Shares, fill = Win.Shares)) + geom_col() + scale_fill_gradient2( low = "red", # negative mid = "grey", # zero high = "dark green", # positive midpoint = 0 ) + labs(x = "Win Shares", y = "", title = "How player stats affect Win Shares", subtitle = "Maximize per game statistics and pick a high seed", caption = "Data collected from https://www.basketball-reference.com/ on April 27, 2026") + scale_y_discrete(labels = c( FG. = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game" )) + xlim(-0.35, 0.82) + theme_classic() + theme( axis.line.y = element_blank(), axis.ticks.y = element_blank(), strip.background = element_blank(), legend.position = "none", strip.text = element_text(face = "bold", size = 12), plot.title = element_text(face = "bold", size = 16), plot.subtitle = element_text(face = "italic", size = 14) )```:::...however, players that can *maximize* their per-game statistics tend to be more valuable players on the court. @cr-svw-annotated:::{#cr-svw-annotated}```{r, echo=FALSE, include=TRUE}win.shares.cor %>% ggplot(aes(y = fct_reorder(term, Win.Shares), x = Win.Shares, fill = Win.Shares)) + geom_col() + scale_fill_gradient2( low = "red", # negative mid = "grey", # zero high = "dark green", # positive midpoint = 0 ) + labs(x = "Win Shares", y = "", title = "How player stats affect Win Shares", subtitle = "Maximize per game statistics and pick a high seed", caption = "Data collected from https://www.basketball-reference.com/ on April 27, 2026") + scale_y_discrete(labels = c( FG. = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game" )) + annotate("rect", xmin = -0.02, xmax = 0.82, ymin = 8.51, ymax = 15.51, fill = NA, color = "red", linetype = "dashed") + theme_classic() + xlim(-0.35, 0.82) + theme( axis.line.y = element_blank(), axis.ticks.y = element_blank(), strip.background = element_blank(), legend.position = "none", strip.text = element_text(face = "bold", size = 12), plot.title = element_text(face = "bold", size = 16), plot.subtitle = element_text(face = "italic", size = 14) )```:::Additionally, if you can *minimize* your draft pick number -- that it, be a number close to 1 (i.e., be first pick) -- you tend to do well in terms of win shares. @cr-svw-annotated2:::{#cr-svw-annotated2}```{r, echo=FALSE, include=TRUE}win.shares.cor %>% ggplot(aes(y = fct_reorder(term, Win.Shares), x = Win.Shares, fill = Win.Shares)) + geom_col() + scale_fill_gradient2( low = "red", # negative mid = "grey", # zero high = "dark green", # positive midpoint = 0 ) + labs(x = "Win Shares", y = "", title = "How player stats affect Win Shares", subtitle = "Maximize per game statistics and pick a high seed", caption = "Data collected from https://www.basketball-reference.com/ on April 27, 2026") + scale_y_discrete(labels = c( FG. = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game" )) + annotate("rect", xmin = -0.32, xmax = 0.01, ymin = 0.5, ymax = 1.5, fill = NA, color = "red", linetype = "dashed") + theme_classic() + xlim(-0.35, 0.82) + theme( axis.line.y = element_blank(), axis.ticks.y = element_blank(), strip.background = element_blank(), legend.position = "none", strip.text = element_text(face = "bold", size = 12), plot.title = element_text(face = "bold", size = 16), plot.subtitle = element_text(face = "italic", size = 14) )```:::::::::::{.cr-section}Speaking of draft pick... @cr-draft-blank:::{#cr-draft-blank}```{r, echo=FALSE, include=TRUE}df %>% ggplot(aes(x = factor(Draft.Pick), y = Points.Per.Game)) + scale_fill_gradient(low = "dark green", high = "lightgrey") + scale_x_discrete( breaks = c("1", "10", "20", "30", "40", "50", NA) ) + labs(x = "Draft Pick", y = "Points Per Game", title = "Points Per Game by Draft Pick", subtitle = "Higher picks tend to score more, but variance grows for late picks") + theme_classic() + theme( legend.position = "none", plot.title = element_text(size = 14, face = "bold"), plot.subtitle = element_text(size = 12, face = "italic") )```:::This graph illustrates the points-per-game scoring from each draft pick slot across all years of our dataset. @cr-draft-filled:::{#cr-draft-filled}```{r, echo=FALSE, include=TRUE}df %>% ggplot(aes(x = factor(Draft.Pick), y = Points.Per.Game)) + geom_boxplot() + scale_fill_gradient(low = "dark green", high = "lightgrey") + scale_x_discrete( breaks = c("1", "10", "20", "30", "40", "50", NA) ) + labs(x = "Draft Pick", y = "Points Per Game", title = "Points Per Game by Draft Pick", subtitle = "Higher picks tend to score more, but variance grows for late picks") + theme_classic() + theme( legend.position = "none", plot.title = element_text(size = 14, face = "bold"), plot.subtitle = element_text(size = 12, face = "italic") )```:::Higher picks score, on average, more points per game than players of lower draft slots. A notable difference is that the NA category is very widespread in its outcomes. This is due to undrafted free agents and international players who were not formally drafted, but were successful anyways. @cr-draft-annotated:::{#cr-draft-annotated}```{r, echo=FALSE, include=TRUE}df %>% ggplot(aes(x = factor(Draft.Pick), y = Points.Per.Game, fill = Draft.Pick)) + geom_boxplot(outlier.color = "red", outlier.alpha = 0.5) + scale_fill_gradient(low = "dark green", high = "lightgrey") + scale_x_discrete( breaks = c("1", "10", "20", "30", "40", "50", NA) ) + labs(x = "Draft Pick", y = "Points Per Game", title = "Points Per Game by Draft Pick", subtitle = "Higher picks tend to score more, but variance grows for late picks") + theme_classic() + theme( legend.position = "none", plot.title = element_text(size = 14, face = "bold"), plot.subtitle = element_text(size = 12, face = "italic") )```:::::::```{r, echo=FALSE, include=FALSE}wnba2$Draft.Pick[wnba2$Draft.Pick == "Undrafted"] <- NAwnba2$Draft.Pick <- as.numeric(wnba2$Draft.Pick)wnba2 <- wnba2[!is.na(wnba2$Draft.Pick), ]# Step 1: clean dataclean_data <- wnba2 %>% mutate( Draft.Pick = as.character(Draft.Pick), Draft.Pick[Draft.Pick %in% c("Undrafted", "")] <- NA, Draft.Pick = as.numeric(Draft.Pick) ) %>% filter(!is.na(Draft.Pick)) %>% select(where(is.numeric)) %>% na.omit() # ⚠️ THIS is key: removes any remaining NA rows# Step 2: create X and y from SAME datasetx <- model.matrix(Draft.Pick ~ ., clean_data)[, -1]y <- clean_data$Draft.Pick# Step 3: run LASSOcv_model <- cv.glmnet(x, y, alpha = 1)lasso_model <- glmnet(x, y, alpha = 1, lambda = cv_model$lambda.min)# Step 4: extract important variablesimportant_vars <- coef(lasso_model)important_vars[important_vars != 0]coef_df <- as.matrix(coef(lasso_model)) %>% as.data.frame()# Rename columncolnames(coef_df)[1] <- "coefficient"# Add variable names and clean upcoef_df <- coef_df %>% mutate(variable = rownames(.)) %>% filter(coefficient != 0) %>% # keep only important variables arrange(desc(abs(coefficient)))```::::{.cr-section}When we look at the most significant variables that effect a player's draft pick, through a LASSO model... @cr-lasso-blank:::{#cr-lasso-blank}```{r, echo=FALSE, include=TRUE}coef_df %>% filter(variable != "(Intercept)") %>% ggplot(aes(y = fct_reorder(variable, coefficient), x = coefficient)) + scale_y_discrete(labels = c( FG = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game", Win.Shares = "Win Shares" )) + labs(x = "Improvement in Draft Pick", y = "", title = "LASSO: Most Significant Variables to Improve Draft Pick", subtitle = "3 Point % and Steals per Game are most valuable attributes") + theme_classic() + theme( plot.title = element_text(size = 14, face = "bold"), plot.subtitle = element_text(size = 12, face = "italic") )```:::...we see the percentage of 3-pointers is most important according to the LASSO model. Although still a variable to be considered, the free throws are not a meaningful variable to look at for draft selection. @cr-lasso-filled:::{#cr-lasso-filled}```{r, echo=FALSE, include=TRUE}coef_df %>% filter(variable != "(Intercept)") %>% ggplot(aes(y = fct_reorder(variable, coefficient), x = coefficient)) + geom_point() + scale_y_discrete(labels = c( FG = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game", Win.Shares = "Win Shares" )) + labs(x = "Improvement in Draft Pick", y = "", title = "LASSO: Most Significant Variables to Improve Draft Pick", subtitle = "3 Point % and Steals per Game are most valuable attributes") + theme_classic() + theme( plot.title = element_text(size = 14, face = "bold"), plot.subtitle = element_text(size = 12, face = "italic") )```:::::::```{r, echo=FALSE, include=FALSE}# Step 1: clean data (same logic as before)clean_data <- wnba2 %>% mutate( Draft.Pick = as.character(Draft.Pick), Draft.Pick[Draft.Pick %in% c("Undrafted", "")] <- NA, Draft.Pick = as.numeric(Draft.Pick) ) %>% filter(!is.na(Draft.Pick)) %>% select(where(is.numeric)) %>% na.omit()# Step 2: run random forestset.seed(123)rf_model <- randomForest( Draft.Pick ~ ., data = clean_data, importance = TRUE, ntree = 500)# Step 3: extract variable importanceimportance_df <- as.data.frame(importance(rf_model))importance_df$variable <- rownames(importance_df)# Sort by importanceimportance_df <- importance_df %>% arrange(desc(IncNodePurity))```::::{.cr-section}We also created a random forest to explore the relationship between variables related to drafting and the percentage error in picking the right player. @cr-rf-blank:::{#cr-rf-blank}```{r, echo=FALSE, include=TRUE}importance_df %>% ggplot(aes(y = fct_reorder(variable, `%IncMSE`), x = `%IncMSE`)) + scale_y_discrete(labels = c( `FG.` = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game", Win.Shares = "Win Shares" )) + labs(x = "Percent Increase in MSE", y = "", title = "Random Forest: Most Valuable Stats for Draft Pick", subtitle = "Excluding Year Drafted or Points per Game makes a worse model") + theme_classic() + theme( plot.title = element_text(size = 14, face = "bold"), plot.subtitle = element_text(size = 12, face = "italic") )```:::The percentage increase in MSE measures how much the prediction error increases if a variable is removed. The higher the MSE, the more important that variable is, such as points per game and assists per game, to name a few. @cr-rf-filled:::{#cr-rf-filled}```{r, echo=FALSE, include=TRUE}importance_df %>% ggplot(aes(y = fct_reorder(variable, `%IncMSE`), x = `%IncMSE`)) + geom_point() + scale_y_discrete(labels = c( `FG.` = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game", Win.Shares = "Win Shares" )) + labs(x = "Percent Increase in MSE", y = "", title = "Random Forest: Most Valuable Stats for Draft Pick", subtitle = "Excluding Year Drafted or Points per Game makes a worse model") + theme_classic() + theme( plot.title = element_text(size = 14, face = "bold"), plot.subtitle = element_text(size = 12, face = "italic") )```:::::::::::{.cr-section}We also created an **ordinary linear regression model (OLR)** to explore relationships between various WNBA stats and Win Shares in more detail. @cr-olr-blank:::{#cr-olr-blank}```{r, echo=FALSE, include=TRUE}model1 <- lm(Win.Shares ~ . , data = df %>% select(-c(Year, Player.Name, Team, College...Origin)))coef_df <- tidy(model1)coef_df %>% filter(term != "(Intercept)") %>% ggplot(aes(y = fct_reorder(term, estimate), x = estimate)) + scale_y_discrete(labels = c( FG = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game" )) + labs(x = "Improvement in Win Shares", y = "", title = "OLR: Most Important Variables for Increasing Win Shares", subtitle = "In-game performance outweighs most other variables") + theme_classic() + theme( plot.title = element_text(size = 14, face = "bold"), plot.subtitle = element_text(size = 12, face = "italic") )```:::This plot illustrates the importance of different statistical categories in relation to win shares. The further to the right a category is, the better an improvement in that category does to a player’s win shares. Meaning, a one unit increase in a player’s field goal percentage has a dramatically positive effect on that player's win shares. The inverse is true for turnovers per game. @cr-olr-filled:::{#cr-olr-filled}```{r, echo=FALSE, include=TRUE}coef_df %>% filter(term != "(Intercept)") %>% ggplot(aes(y = fct_reorder(term, estimate), x = estimate)) + geom_point() + scale_y_discrete(labels = c( FG = "Field Goals", Steals.Per.Game = "Steals per Game", `FT.` = "Free Throws", Blocks.Per.Game = "Blocks per Game", Assists.Per.Game = "Assists per Game", Points.Per.Game = "Points per Game", Rebounds.Per.Game = "Rebounds per Game", `PositionF-C` = "Position: Forward-Center", `X3P.` = "3 Point %", PositionF = "Position: Forward", `PositionG-F` = "Position: Guard-Forward", PositionG = "Position: Guard", Weight = "Weight", Draft.Pick = "Draft Pick", Height = "Height", Minutes.Per.Game= "Minutes per Game", `PositionC-F` = "Position: Center-Forward", Year.Drafted = "Year Drafted", `PositionF-G` = "Position: Forward-Guard", Turnovers.Per.Game = "Turnovers per Game" )) + labs(x = "Improvement in Win Shares", y = "", title = "OLR: Most Important Variables for Increasing Win Shares", subtitle = "In-game performance outweighs most other variables") + theme_classic() + theme( plot.title = element_text(size = 14, face = "bold"), plot.subtitle = element_text(size = 12, face = "italic") )```:::::::## InterpretationsAccording to the data that we collected, it appears that the pick that a player was selected at has an influence over the future success of that player. The player selected first overall tends to have an outsized level of success, with fewer wins generated by the 2nd through 6th picks. There is a drop of nearly two full win shares on average between first overall picks and those taken anywhere in the top six, and that gap continues to widen as selections move deeper into the draft. Players taken between seventh and fifteenth average just over one win share per season, while undrafted players who make a roster average just 0.6. The relationship is real but it is worth noting that it functions more as a proxy for talent level than as a causal mechanism. Being picked first does not make a player better; it reflects that evaluators already believed they were.That said, draft position explains only about ten percent of the variation in win shares when modeled on its own alongside height and weight. Physical attributes, despite their intuitive appeal as predictors, turn out to have very limited standalone power. Height carries a small positive signal, taller players tend to accumulate more win shares in part because the center and forward positions naturally generate more rebounds and blocks, but weight adds almost nothing once height is accounted for. The physical model as a whole leaves ninety percent of the outcome unexplained.The performance statistics model tells a far more complete story. Points per game, rebounds per game, assists per game, blocks per game, steals per game, field goal percentage and free throw percentage together explain roughly 74 percent of win shares variance in a standard linear model, and a random forest using the same inputs pushes that figure to 76 percent. Scoring volume is the single most important factor by a wide margin, accounting for nearly 64 percent of the random forest's predictive power on its own. But shooting efficiency amplifies or diminishes that volume in ways that matter enormously. A player scoring fifteen points per game on 50 percent shooting generates substantially more value than the same volume on 38 percent.The most counterintuitive finding is the role of turnovers. Of all the variables in the model, turnovers per game carry the largest negative coefficient, sitting at nearly negative one full win share per turnover per game. That means a single additional turnover per game costs a player roughly as much in win shares as a steal or an assist is worth in the positive direction. Players who protect the ball are quietly among the most valuable contributors in the league regardless of how prominently they appear in the box score.## Answer to QuestionThe answer to the original question is that on-court production is what drives success in the WNBA, and the specific combination of scoring efficiently, distributing the ball, defending actively and limiting turnovers separates the most impactful players from the rest. Physical size and draft pedigree provide a foundation, but they account for a small fraction of what determines how much a player actually contributes once the game is being played. The five players with the highest career win shares in our dataset, Tamika Catchings, Nneka Ogwumike, Diana Taurasi, Sylvia Fowles and Lauren Jackson, all share one characteristic above any other. They were relentless producers who made good decisions with the ball, and they did it consistently across many seasons.